解析 XML 文档时,另一个有用的技巧是查找特定元素的所有直接子元素。例如,在语法文件中,ref 元素可以有多个 p 元素,每个元素可以包含许多内容,包括其他 p 元素。您只想找到作为 ref 子元素的 p 元素,而不是作为其他 p 元素子元素的 p 元素。
您可能认为可以使用 getElementsByTagName 来实现这一点,但不能。 getElementsByTagName 会递归搜索并为找到的所有元素返回一个列表。由于 p 元素可以包含其他 p 元素,因此您不能使用 getElementsByTagName,因为它会返回您不想要的嵌套 p 元素。要仅查找直接子元素,您需要自己动手。
示例 10.16. 查找直接子元素
def randomChildElement(self, node): choices = [e for e in node.childNodes if e.nodeType == e.ELEMENT_NODE]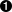
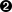
chosen = random.choice(choices)
return chosen
| 如您在 示例 9.9,“获取子节点” 中看到的,childNodes 属性返回元素的所有子节点的列表。 | |
| 但是,如您在 示例 9.11,“子节点可以是文本” 中看到的,childNodes 返回的列表包含所有不同类型的节点,包括文本节点。这不是您在这里要查找的内容。您只想要作为元素的子节点。 | |
| 每个节点都有一个 nodeType 属性,可以是 ELEMENT_NODE、TEXT_NODE、COMMENT_NODE 或任何其他值。完整的值列表位于 xml.dom 包中的 __init__.py 文件中。(有关包的更多信息,请参阅 第 9.2 节,“包”。)但您只对作为元素的节点感兴趣,因此您可以过滤列表以仅包含 nodeType 为 ELEMENT_NODE 的节点。 | |
| 拥有了实际元素列表后,选择一个随机元素就很容易了。 Python 附带一个名为 random 的模块,其中包含几个有用的函数。 random.choice 函数接受一个包含任意数量项的列表,并返回一个随机项。例如,如果 ref 元素包含多个 p 元素,则 choices 将是一个 p 元素列表,而 chosen 最终将被分配为其中一个随机选择的元素。 |