正如我所说,解析 XML 文档实际上非常简单:只需一行代码。如何处理解析后的结果取决于您。
示例 9.8. 加载 XML 文档(这次是真的)
>>> from xml.dom import minidom 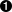 >>> xmldoc = minidom.parse('~/diveintopython/common/py/kgp/binary.xml')
>>> xmldoc = minidom.parse('~/diveintopython/common/py/kgp/binary.xml') 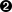 >>> xmldoc
>>> xmldoc  <xml.dom.minidom.Document instance at 010BE87C>
>>> print xmldoc.toxml()
<xml.dom.minidom.Document instance at 010BE87C>
>>> print xmldoc.toxml()  <?xml version="1.0" ?>
<grammar>
<ref id="bit">
<p>0</p>
<p>1</p>
</ref>
<ref id="byte">
<p><xref id="bit"/><xref id="bit"/><xref id="bit"/><xref id="bit"/>\
<xref id="bit"/><xref id="bit"/><xref id="bit"/><xref id="bit"/></p>
</ref>
</grammar>
<?xml version="1.0" ?>
<grammar>
<ref id="bit">
<p>0</p>
<p>1</p>
</ref>
<ref id="byte">
<p><xref id="bit"/><xref id="bit"/><xref id="bit"/><xref id="bit"/>\
<xref id="bit"/><xref id="bit"/><xref id="bit"/><xref id="bit"/></p>
</ref>
</grammar>
|
|
正如您在上一节中所见,这行代码从 xml.dom 包中导入了 minidom 模块。
|
|
|
下面这行代码完成了所有工作:minidom.parse 接受一个参数并返回 XML 文档的解析表示形式。该参数可以是多种类型;在本例中,它只是本地磁盘上 XML 文档的文件名。(要跟随示例操作,您需要更改路径以指向您下载的示例目录。)但您也可以传递文件对象,甚至是类文件对象。本章稍后将利用这种灵活性。
|
|
|
minidom.parse 返回的对象是一个 Document 对象,它是 Node 类的子类。这个 Document 对象是复杂树状结构的根级别,该结构由相互关联的 Python 对象组成,这些对象完整地表示您传递给 minidom.parse 的 XML 文档。
|
|
|
toxml 是 Node 类的一个方法(因此在您从 minidom.parse 获得的 Document 对象上也可用)。toxml 打印出此 Node 表示的 XML。对于 Document 节点,这将打印出整个 XML 文档。
|
现在您已经在内存中拥有了一个 XML 文档,您可以开始遍历它了。
示例 9.9. 获取子节点
>>> xmldoc.childNodes
[<DOM Element: grammar at 17538908>]
>>> xmldoc.childNodes[0]
<DOM Element: grammar at 17538908>
>>> xmldoc.firstChild
<DOM Element: grammar at 17538908>
|
|
每个 Node 都有一个 childNodes 属性,它是一个 Node 对象列表。一个 Document 始终只有一个子节点,即 XML 文档的根元素(在本例中为 grammar 元素)。
|
|
|
要获取第一个(在本例中也是唯一一个)子节点,只需使用常规列表语法。请记住,这里没有什么特别之处;这只是一个包含常规 Python 对象的常规 Python 列表。
|
|
|
由于获取节点的第一个子节点是一个有用且常见的操作,因此 Node 类有一个 firstChild 属性,它等同于 childNodes[0]。(还有一个 lastChild 属性,它等同于 childNodes[-1]。)
|
示例 9.10. toxml 适用于任何节点
>>> grammarNode = xmldoc.firstChild
>>> print grammarNode.toxml()
<grammar>
<ref id="bit">
<p>0</p>
<p>1</p>
</ref>
<ref id="byte">
<p><xref id="bit"/><xref id="bit"/><xref id="bit"/><xref id="bit"/>\
<xref id="bit"/><xref id="bit"/><xref id="bit"/><xref id="bit"/></p>
</ref>
</grammar>
|
|
由于 toxml 方法是在 Node 类中定义的,因此它适用于任何 XML 节点,而不仅仅是 Document 元素。
|
示例 9.11. 子节点可以是文本
>>> grammarNode.childNodes
[<DOM Text node "\n">, <DOM Element: ref at 17533332>, \
<DOM Text node "\n">, <DOM Element: ref at 17549660>, <DOM Text node "\n">]
>>> print grammarNode.firstChild.toxml()
>>> print grammarNode.childNodes[1].toxml()
<ref id="bit">
<p>0</p>
<p>1</p>
</ref>
>>> print grammarNode.childNodes[3].toxml()
<ref id="byte">
<p><xref id="bit"/><xref id="bit"/><xref id="bit"/><xref id="bit"/>\
<xref id="bit"/><xref id="bit"/><xref id="bit"/><xref id="bit"/></p>
</ref>
>>> print grammarNode.lastChild.toxml() 
|
|
查看 binary.xml 中的 XML,您可能会认为 grammar 只有两个子节点,即两个 ref 元素。但您遗漏了一些东西:回车符!在 '<grammar>' 之后和第一个 '<ref>' 之前是一个回车符,这段文本也算作 grammar 元素的子节点。类似地,每个 '</ref>' 之后都有一个回车符;这些也算作子节点。所以 grammar.childNodes 实际上是一个包含 5 个对象的列表:3 个 Text 对象和 2 个 Element 对象。
|
|
|
第一个子节点是一个 Text 对象,表示 '<grammar>' 标记之后和第一个 '<ref>' 标记之前的回车符。
|
|
|
第二个子节点是一个 Element 对象,表示第一个 ref 元素。
|
|
|
第四个子节点是一个 Element 对象,表示第二个 ref 元素。
|
|
|
最后一个子节点是一个 Text 对象,表示 '</ref>' 结束标记之后和 '</grammar>' 结束标记之前的回车符。
|
示例 9.12. 一直深入到文本
>>> grammarNode
<DOM Element: grammar at 19167148>
>>> refNode = grammarNode.childNodes[1]
>>> refNode
<DOM Element: ref at 17987740>
>>> refNode.childNodes
[<DOM Text node "\n">, <DOM Text node " ">, <DOM Element: p at 19315844>, \
<DOM Text node "\n">, <DOM Text node " ">, \
<DOM Element: p at 19462036>, <DOM Text node "\n">]
>>> pNode = refNode.childNodes[2]
>>> pNode
<DOM Element: p at 19315844>
>>> print pNode.toxml()
<p>0</p>
>>> pNode.firstChild
<DOM Text node "0">
>>> pNode.firstChild.data
u'0'
|
|
正如您在前面的示例中看到的,第一个 ref 元素是 grammarNode.childNodes[1],因为 childNodes[0] 是回车符的 Text 节点。
|
|
|
ref 元素有它自己的一组子节点,一个用于回车符,一个用于空格,一个用于 p 元素,等等。
|
|
|
您甚至可以在文档深处嵌套使用 toxml 方法。
|
|
|
p 元素只有一个子节点(您无法从本例中看出这一点,但如果您不相信我,请查看 pNode.childNodes),它是一个表示单个字符 '0' 的 Text 节点。
|
|
|
Text 节点的 .data 属性为您提供了该文本节点表示的实际字符串。但是字符串前面的 'u' 是什么意思呢?这个问题的答案需要用一整节来解释。
|