XML 元素可以有一个或多个属性,一旦你解析了一个 XML 文档,访问它们就变得非常简单。
在本节中,你将使用在上一节中看到的 binary.xml 语法文件。
| 本节可能会让人有点困惑,因为有一些重叠的术语。 XML 文档中的元素有属性,Python 对象也有属性。当你解析一个 XML 文档时,你会得到一堆表示 XML 文档所有部分的 Python 对象,其中一些 Python 对象表示 XML 元素的属性。但是表示 (XML) 属性的 (Python) 对象也有 (Python) 属性,这些属性用于访问该对象所表示的 (XML) 属性的各个部分。我告诉过你这很让人困惑。我欢迎大家就如何更清晰地区分这些内容提出建议。 | |
例 9.24. 访问元素属性
>>> xmldoc = minidom.parse('binary.xml') >>> reflist = xmldoc.getElementsByTagName('ref') >>> bitref = reflist[0] >>> print bitref.toxml() <ref id="bit"> <p>0</p> <p>1</p> </ref> >>> bitref.attributes<xml.dom.minidom.NamedNodeMap instance at 0x81e0c9c> >>> bitref.attributes.keys()
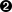
[u'id'] >>> bitref.attributes.values()
[<xml.dom.minidom.Attr instance at 0x81d5044>] >>> bitref.attributes["id"]
<xml.dom.minidom.Attr instance at 0x81d5044>
| 每个 Element 对象都有一个名为 attributes 的属性,它是一个 NamedNodeMap 对象。这听起来很吓人,但其实不是,因为 NamedNodeMap 是一个类似于字典的对象,所以你已经知道如何使用它了。 | |
| 将 NamedNodeMap 视为字典,你可以使用 attributes.keys() 获取该元素属性名称的列表。此元素只有一个属性,即 'id'。 | |
| 属性名称,就像 XML 文档中的所有其他文本一样,都存储在 Unicode 中。 | |
| 同样将 NamedNodeMap 视为字典,你可以使用 attributes.values() 获取属性值的列表。这些值本身就是 Attr 类型的对象。你将在下一个例子中看到如何从这个对象中获取有用的信息。 | |
| 仍然将 NamedNodeMap 视为字典,你可以使用普通的字典语法,按名称访问单个属性。(特别注意的读者可能已经知道 NamedNodeMap 类是如何完成这个巧妙的技巧的:通过定义一个__getitem__ 特殊方法。其他读者可以放心,他们不需要了解它是如何工作的,就可以有效地使用它。) |
例 9.25. 访问单个属性
>>> a = bitref.attributes["id"] >>> a <xml.dom.minidom.Attr instance at 0x81d5044> >>> a.name
| Attr 对象完全表示单个 XML 元素的单个 XML 属性。属性的名称(与你在 bitref.attributes NamedNodeMap 伪字典中用于查找此对象的名称相同)存储在 a.name 中。 | |
| 此 XML 属性的实际文本值存储在 a.value 中。 |
| 与字典一样,XML 元素的属性没有顺序。属性在原始 XML 文档中可能以特定顺序列出,并且 Attr 对象在 XML 文档被解析为 Python 对象时可能以特定顺序列出,但这些顺序是任意的,不应具有特殊含义。你应该始终按名称访问单个属性,就像字典的键一样。 | |